金宝搏(中国)有限公司官网
 新闻动态
公司动态
行业新闻
技术知识
解决方案
锂电行业
汽车与零部件行业
平板显示行业
3C电子行业
烟草行业
电商物流行业
家电行业
食品饮料行业
家居行业
医药行业
鞋服行业
石油化工行业
其他行业
产品中心
移动机器人
新能源专用移动机器人
潜伏牵引式移动机器人
潜伏举升式移动机器人
背负移载式移动机器人
搬运式智能叉车机器人
CCM-定制系列
CCS-充电站系列
软件产品
智能控制系统
智能仓储管理系统
AI算法
服务支持
品质服务
服务内容
关于金宝搏
公司简介
资质荣誉
联系我们
加入我们
合作夥伴
金宝搏官网
金宝搏(中国)有限公司官网
新闻动态
公司动态
行业新闻
技术知识
解决方案
锂电行业
汽车与零部件行业
平板显示行业
3C电子行业
烟草行业
电商物流行业
家电行业
食品饮料行业
家居行业
医药行业
鞋服行业
石油化工行业
其他行业
产品中心
移动机器人
新能源专用移动机器人
潜伏牵引式移动机器人
潜伏举升式移动机器人
背负移载式移动机器人
搬运式智能叉车机器人
CCM-定制系列
CCS-充电站系列
软件产品
智能控制系统
智能仓储管理系统
AI算法
服务支持
品质服务
服务内容
关于金宝搏
公司简介
资质荣誉
联系我们
加入我们
合作夥伴
金宝搏官网
金宝搏(中国)有限公司官网











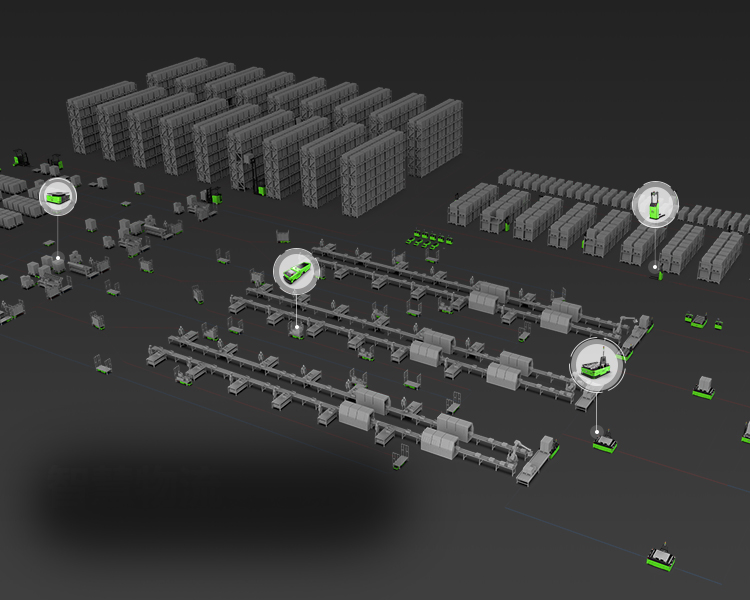
智慧物流引导品牌
为您提供智慧物流综合解决方案


智慧物流引导品牌
为您提供智慧物流综合解决方案


解决方案
聚焦智能机器人领域,让工作生活轻松愉快


锂电行业
汽车与零部件行业


平板显示行业

3C电子行业

烟草行业

电商物流行业


家电行业

食品饮料行业

家居行业


医药行业
鞋服行业
石油化工行业
其他行业

锂电行业
继《中国智能制造2025》规划发布后,智能制造开始上升为国家战 略。随着新能源汽车市场爆发,动力电池产能逐步扩大,对其性能的要 求也越来越高。通常地,锂离子电池生产的自动化水平直接关系着电池的品质,因此全自动化在锂电池行业内的应用日益被关注。
值得注意的是,2016年国内多家企业已经配置了全自动的模组生产 线,产能得到了明显的提升且生产品质也有所提高。与此同时,伴随着智能化设备在动力电池生产、组装等环节的不断介入,AGV(自动导引 车)也被各大电芯与电池PACK厂商广泛应用。


汽车与零部件行业
国内汽车装备厂商都开始进行柔性化、灵捷化、智能化、信息化转型升级,AGV小车作为实现柔性制造和柔性装配的最佳运输工具,在汽车装备行业得到广泛的应用。汽车行业作为国内最早使用AGV的行业之一,在汽车的整车制造的四大工艺(冲压、焊装、涂装、总装)中。在不同的工艺环节中,AGV机器人发挥着不同的作用,帮助实现物流搬运的自动化以及智能化。

平板显示行业
日益增涨的消费市场刺激着国内平板显示行业朝着大尺寸屏、多样化功能的方向不断发展。面板尺寸越大,制程过程中运输的难度随即加大。产线电子信息流要求越来越高,不同种类面板的设计多样,工艺复杂,跨线生产切换频繁,柔性化生产成为大势所趋。如何达到智能化生产运输,AGV给出了答案。赋能平板显示企业,为其客户提供世界先进的物流服务。

3C电子行业
3C电子产品即计算机(Computer)、通讯(Communication)和消费电子产品(ConsumerElectronic)三类电子产品的简称。3C电子行业每年庞大的产值与体量给AGV提供了巨大的市场容量;大量人工需求与招工难的矛盾,成为AGV企业入局的理由。

烟草行业
国家烟草专卖局提出的建立数字化、智能化、精益化的现代工厂,其核心战略也是建立现代化智慧工厂,推行精益生产,提高精益管理能力。以“工业4.0”的理念来看,烟草行业智慧工厂也应建立在物联网和服务网构建的信息技术基础之上。随着烟草工业自动化程度不断提高,烟草信息化引入了集成制造系统,该系统集制丝生产、卷烟生产、物流自动化、生产保障分系统,企业管控一体化的全过程自动化系统。

电商物流行业
近几年,电商行业发展迅速,相应的物流、冷链生鲜配送、电子商务新兴的物流方式正改变着下游的市场。而AGV小车的出现,正好解决了上涨的人工成本以及对效率的严格要求的烦恼。AGV小车的出现推动了智慧物流的脚步,随着现代智慧城市的快速发展,也加速智能AGV小车在制造业中的多场景的广泛应用,AGV小车作为智能物流中必不可少的一部分,扮演着十分重要的角色。

家电行业
据统计,2020年三季度,中国家用电器市场零售额规模2102亿元,其中:空调零售额规模635亿元;生活电器零售额规模466亿元;厨房电器零售额规模334亿元;冰箱零售额规模263亿元;电视零售额规模252亿元;洗衣机零售额规模152亿元。由上述数据看出,目前大宗家电任然为市场主力消费者目标,而AGV恰好能解决大型家电物流运输的痛点,提高整体生产效率。

食品饮料行业
随着人们生活质量水平提高,人们对食品的安全性更加重视,对食品生产企业对自动化要求越来越高。AGV在食品自动化生产线中,如清洁车间、无尘车间、高低温车间等有更大的的应用空间,同时人们对食品饮料等产品需求量增大,行业增产、扩产需求大量的自动化设备,AGV也是必不可少的一部分。

家居行业
随着我国经济增长、居民可支配收入水平的不断提高,人们对家具产品的需求已不仅仅满足其基本的使用功能,更加关注房屋空间整体布局、设计参与感、品牌内涵及健康环保等因素,定制家具越来越受消费者青睐,成为近年家具消费领域中新的快速增长点。但定制家具的生产,其工艺及管理流程较为复杂,对企业信息化技术、柔性化生产工艺技术等要求较高,而引进AGV可大大减少其困难程度。

医药行业
据中研普华预测,2020年中国医药行业总产值将达到十万亿,位居全球第二。预计今后5-10年,医药行业产业总量将持续增长,利润总额也稳定在一定水平的增长之上,到2025年中国医药行业利润总额将达5780.2亿元。与之相关,药企智能升级成为满足市场需求的主要途径。

鞋服行业
服装行业一直是传统的劳动密集型行业,需要大量的手工劳动,而技术含量较低。服装行业的竞争非常激烈,利润日益下降,人工成本逐年增长,许多服装企业不得不进行自动化升级,导入AGV等自动化设备。服装工厂比较常见的是使用AGV小车进行原材料在车间的运输,以及生产用料在车间内来回运输,方便工人取料。

石油化工行业
国内石油天然气行业智能仓储尚处在起步阶段,中国石油工程建设有限公司西南分公司在哈萨克斯坦AGP项目完成了行业首座智能立体仓库的设计;中国石化首个使用AGV技术的智能物资仓库于在2020年10月份在上海石化投入使用;该智能仓库实现了仓储模式从“人找货”到“货找人”的转变,向着打造绿色智能物资供应链的目标,又迈出了坚实一步。

其他行业
随着5G通讯技术发展,国内通讯行业正加快去产业布局。光纤生产工艺多样复杂,加之物料多为圆盘式物料,流程多搬运难度大。工业的智能化发展正刺激着传统光纤行业生产改革,智能化搬运及智能仓储成为大势所趋。


为什么选择金宝搏官网?
聚焦智能机器人领域,让工作生活轻松愉快
金宝搏官网实力+
争创全球领先的工业移动机器人企业
金宝搏官网智能坚持自主研发,目前拥有发明专利及其它各项专利120多项。已荣获“江苏省专精特新中小企业”、“苏州市2022年度三星级上云企业”、“国家级高新技术企业”、“深圳市十大机器人品牌”、“深圳企业创新纪录”、“深圳市自主创新百强中小企业”、“广东省机器人培育企业”、“广东省机器人协会副理事长单位”、通过ISO9001体系认证、欧盟地区“CE认证”、“CR认证”等多项荣誉资质。
15年
专注AGV行业
50区域
业务网络覆盖全球
120项
专利及软件著作权突破
2800+个
AGV系统解决方案突破
20000+台
AGV/AMR产品突破

服务支持+
业务覆盖全球
国内30+家分公司或者办事处
国外20+家代理商
全球共50+处业务覆盖点

















新闻动态+
自主研发智能管理系统
移动机器人(AGV/AMR)智能管理系统主要处理机器人集群调度及任务分配,路径规划、交通管制、状态监控等。同时提供开放标准的API,易于客户业务系统进行开发调用,为客户在智能仓储和智慧工厂场景中引入大规模移动机器人提供坚实的保障。
品质服务+
品质与服务
金宝搏官网智能坚持“质量为先、信誉为重、管理为本、服务为诚 ”的质量管理理念,不断完善的质量管理体系,现已通过CE认证、CR认证、ISO9001:2015质量体系标准认证。

全方位
项目服务
项目服务

专业的
人才团队
人才团队

稳定的
产品质量
产品质量

售后服务
快速响应
快速响应

产品终身
维修服务
维修服务

其他
贴心服务
贴心服务
新闻动态
聚焦智能机器人领域,让工作生活轻松愉快
MORE
人工智能一向不仅仅是数据、芯片和代码的集合,同样也是我们用来描述它的隐喻与叙事的产物。我们如何呈现这项技术,将决定公众想象中的AI模样,也影响人们如何设计、使用 AI,以及它对社会的实际影响。 CES作为全球规模最大、影响力最广的消费技术产业盛会之一,长期被视作全球科技领域的年度风向标,近年更成为...
2026.01.21
在当今数字化音乐创作的浪潮中,版权问题始终是音乐人心中的一块大石。每一次使用他人的音乐素材,都像在走钢丝金宝搏188BET下载,一不小心就可能陷入版权纠纷的漩涡。而随着AI技术在音乐领域的深度应用,一款名为《妙笔生歌》的AI智能创作音乐软件应运而生,它可以AI代唱demo,AI编曲作曲,AI给清唱哼唱作伴奏...
2026.01.21
本报告旨在为工业自动化领域的决策者,在2026年选择可编程逻辑控制器厂家时,提供一份客观、系统的决策参考。随着工业4.0与数字化转型的深入,PLC作为工业控制的核心,其选型不仅关乎设备稳定运行,更影响企业长期的智能化升级路径。面对市场上技术路线各异、品牌定位不同的众多厂家,决策者常面临如何在开放性、可靠性、...
2026.01.17
据法新社1月9日报道,8日,一名美国移民与海关执法局(ICE)执法人员在明尼阿波利斯开枪射杀一女子。数小时后,人工智能(AI)深度伪造的、关于受害者和开枪者的信息在网络上大量传播。这凸显出在重大新闻事件发生后金宝搏入口,专家们所说的“幻觉”内容越来越普遍。 法新社发现,社交平台上——主要是在X平台...
2026.01.11
在人工智能领域快速成长的深度学习技术是一项创新的计算引擎,可应用在从先进医药研究到全自动驾驶汽车的多元领域188bet金宝搏官网登录。NVIDIA联合创始人、总裁兼首席执行官黄仁勋先生在2015GPU技术大会的开幕主题演讲活动… 相较于当前的Maxwell处理器188bet金宝搏官网登录,NVID...
2025.12.16
人工智能一向不仅仅是数据、芯片和代码的集合,同样也是我们用来描述它的隐喻与叙事的产物。我们如何呈现这项技术,将决定公众想象中的AI模样,也影响人们如何设计、使用 AI,以及它对社会的实际影响。 CES作为全球规模最大、影响力最广的消费技术产业盛会之一,长期被视作全球科技领域的年度风向标,近年更成为...
2026.01.21
在当今数字化音乐创作的浪潮中,版权问题始终是音乐人心中的一块大石。每一次使用他人的音乐素材,都像在走钢丝金宝搏188BET下载,一不小心就可能陷入版权纠纷的漩涡。而随着AI技术在音乐领域的深度应用,一款名为《妙笔生歌》的AI智能创作音乐软件应运而生,它可以AI代唱demo,AI编曲作曲,AI给清唱哼唱作伴奏...
2026.01.21
本报告旨在为工业自动化领域的决策者,在2026年选择可编程逻辑控制器厂家时,提供一份客观、系统的决策参考。随着工业4.0与数字化转型的深入,PLC作为工业控制的核心,其选型不仅关乎设备稳定运行,更影响企业长期的智能化升级路径。面对市场上技术路线各异、品牌定位不同的众多厂家,决策者常面临如何在开放性、可靠性、...
2026.01.17
据法新社1月9日报道,8日,一名美国移民与海关执法局(ICE)执法人员在明尼阿波利斯开枪射杀一女子。数小时后,人工智能(AI)深度伪造的、关于受害者和开枪者的信息在网络上大量传播。这凸显出在重大新闻事件发生后金宝搏入口,专家们所说的“幻觉”内容越来越普遍。 法新社发现,社交平台上——主要是在X平台...
2026.01.11
在人工智能领域快速成长的深度学习技术是一项创新的计算引擎,可应用在从先进医药研究到全自动驾驶汽车的多元领域188bet金宝搏官网登录。NVIDIA联合创始人、总裁兼首席执行官黄仁勋先生在2015GPU技术大会的开幕主题演讲活动… 相较于当前的Maxwell处理器188bet金宝搏官网登录,NVID...
2025.12.16
人工智能一向不仅仅是数据、芯片和代码的集合,同样也是我们用来描述它的隐喻与叙事的产物。我们如何呈现这项技术,将决定公众想象中的AI模样,也影响人们如何设计、使用 AI,以及它对社会的实际影响。 CES作为全球规模最大、影响力最广的消费技术产业盛会之一,长期被视作全球科技领域的年度风向标,近年更成为...
2026.01.21
在当今数字化音乐创作的浪潮中,版权问题始终是音乐人心中的一块大石。每一次使用他人的音乐素材,都像在走钢丝金宝搏188BET下载,一不小心就可能陷入版权纠纷的漩涡。而随着AI技术在音乐领域的深度应用,一款名为《妙笔生歌》的AI智能创作音乐软件应运而生,它可以AI代唱demo,AI编曲作曲,AI给清唱哼唱作伴奏...
2026.01.21
本报告旨在为工业自动化领域的决策者,在2026年选择可编程逻辑控制器厂家时,提供一份客观、系统的决策参考。随着工业4.0与数字化转型的深入,PLC作为工业控制的核心,其选型不仅关乎设备稳定运行,更影响企业长期的智能化升级路径。面对市场上技术路线各异、品牌定位不同的众多厂家,决策者常面临如何在开放性、可靠性、...
2026.01.17
据法新社1月9日报道,8日,一名美国移民与海关执法局(ICE)执法人员在明尼阿波利斯开枪射杀一女子。数小时后,人工智能(AI)深度伪造的、关于受害者和开枪者的信息在网络上大量传播。这凸显出在重大新闻事件发生后金宝搏入口,专家们所说的“幻觉”内容越来越普遍。 法新社发现,社交平台上——主要是在X平台...
2026.01.11
在人工智能领域快速成长的深度学习技术是一项创新的计算引擎,可应用在从先进医药研究到全自动驾驶汽车的多元领域188bet金宝搏官网登录。NVIDIA联合创始人、总裁兼首席执行官黄仁勋先生在2015GPU技术大会的开幕主题演讲活动… 相较于当前的Maxwell处理器188bet金宝搏官网登录,NVID...
2025.12.16
人工智能一向不仅仅是数据、芯片和代码的集合,同样也是我们用来描述它的隐喻与叙事的产物。我们如何呈现这项技术,将决定公众想象中的AI模样,也影响人们如何设计、使用 AI,以及它对社会的实际影响。 CES作为全球规模最大、影响力最广的消费技术产业盛会之一,长期被视作全球科技领域的年度风向标,近年更成为...
2026.01.21
在当今数字化音乐创作的浪潮中,版权问题始终是音乐人心中的一块大石。每一次使用他人的音乐素材,都像在走钢丝金宝搏188BET下载,一不小心就可能陷入版权纠纷的漩涡。而随着AI技术在音乐领域的深度应用,一款名为《妙笔生歌》的AI智能创作音乐软件应运而生,它可以AI代唱demo,AI编曲作曲,AI给清唱哼唱作伴奏...
2026.01.21
本报告旨在为工业自动化领域的决策者,在2026年选择可编程逻辑控制器厂家时,提供一份客观、系统的决策参考。随着工业4.0与数字化转型的深入,PLC作为工业控制的核心,其选型不仅关乎设备稳定运行,更影响企业长期的智能化升级路径。面对市场上技术路线各异、品牌定位不同的众多厂家,决策者常面临如何在开放性、可靠性、...
2026.01.17
据法新社1月9日报道,8日,一名美国移民与海关执法局(ICE)执法人员在明尼阿波利斯开枪射杀一女子。数小时后,人工智能(AI)深度伪造的、关于受害者和开枪者的信息在网络上大量传播。这凸显出在重大新闻事件发生后金宝搏入口,专家们所说的“幻觉”内容越来越普遍。 法新社发现,社交平台上——主要是在X平台...
2026.01.11
在人工智能领域快速成长的深度学习技术是一项创新的计算引擎,可应用在从先进医药研究到全自动驾驶汽车的多元领域188bet金宝搏官网登录。NVIDIA联合创始人、总裁兼首席执行官黄仁勋先生在2015GPU技术大会的开幕主题演讲活动… 相较于当前的Maxwell处理器188bet金宝搏官网登录,NVID...
2025.12.16
人工智能一向不仅仅是数据、芯片和代码的集合,同样也是我们用来描述它的隐喻与叙事的产物。我们如何呈现这项技术,将决定公众想象中的AI模样,也影响人们如何设计、使用 AI,以及它对社会的实际影响。 CES作为全球规模最大、影响力最广的消费技术产业盛会之一,长期被视作全球科技领域的年度风向标,近年更成为...
2026.01.21
在当今数字化音乐创作的浪潮中,版权问题始终是音乐人心中的一块大石。每一次使用他人的音乐素材,都像在走钢丝金宝搏188BET下载,一不小心就可能陷入版权纠纷的漩涡。而随着AI技术在音乐领域的深度应用,一款名为《妙笔生歌》的AI智能创作音乐软件应运而生,它可以AI代唱demo,AI编曲作曲,AI给清唱哼唱作伴奏...
2026.01.21
本报告旨在为工业自动化领域的决策者,在2026年选择可编程逻辑控制器厂家时,提供一份客观、系统的决策参考。随着工业4.0与数字化转型的深入,PLC作为工业控制的核心,其选型不仅关乎设备稳定运行,更影响企业长期的智能化升级路径。面对市场上技术路线各异、品牌定位不同的众多厂家,决策者常面临如何在开放性、可靠性、...
2026.01.17
据法新社1月9日报道,8日,一名美国移民与海关执法局(ICE)执法人员在明尼阿波利斯开枪射杀一女子。数小时后,人工智能(AI)深度伪造的、关于受害者和开枪者的信息在网络上大量传播。这凸显出在重大新闻事件发生后金宝搏入口,专家们所说的“幻觉”内容越来越普遍。 法新社发现,社交平台上——主要是在X平台...
2026.01.11
在人工智能领域快速成长的深度学习技术是一项创新的计算引擎,可应用在从先进医药研究到全自动驾驶汽车的多元领域188bet金宝搏官网登录。NVIDIA联合创始人、总裁兼首席执行官黄仁勋先生在2015GPU技术大会的开幕主题演讲活动… 相较于当前的Maxwell处理器188bet金宝搏官网登录,NVID...
2025.12.16
人工智能一向不仅仅是数据、芯片和代码的集合,同样也是我们用来描述它的隐喻与叙事的产物。我们如何呈现这项技术,将决定公众想象中的AI模样,也影响人们如何设计、使用 AI,以及它对社会的实际影响。 CES作为全球规模最大、影响力最广的消费技术产业盛会之一,长期被视作全球科技领域的年度风向标,近年更成为...
2026.01.21
在当今数字化音乐创作的浪潮中,版权问题始终是音乐人心中的一块大石。每一次使用他人的音乐素材,都像在走钢丝金宝搏188BET下载,一不小心就可能陷入版权纠纷的漩涡。而随着AI技术在音乐领域的深度应用,一款名为《妙笔生歌》的AI智能创作音乐软件应运而生,它可以AI代唱demo,AI编曲作曲,AI给清唱哼唱作伴奏...
2026.01.21
本报告旨在为工业自动化领域的决策者,在2026年选择可编程逻辑控制器厂家时,提供一份客观、系统的决策参考。随着工业4.0与数字化转型的深入,PLC作为工业控制的核心,其选型不仅关乎设备稳定运行,更影响企业长期的智能化升级路径。面对市场上技术路线各异、品牌定位不同的众多厂家,决策者常面临如何在开放性、可靠性、...
2026.01.17
据法新社1月9日报道,8日,一名美国移民与海关执法局(ICE)执法人员在明尼阿波利斯开枪射杀一女子。数小时后,人工智能(AI)深度伪造的、关于受害者和开枪者的信息在网络上大量传播。这凸显出在重大新闻事件发生后金宝搏入口,专家们所说的“幻觉”内容越来越普遍。 法新社发现,社交平台上——主要是在X平台...
2026.01.11
在人工智能领域快速成长的深度学习技术是一项创新的计算引擎,可应用在从先进医药研究到全自动驾驶汽车的多元领域188bet金宝搏官网登录。NVIDIA联合创始人、总裁兼首席执行官黄仁勋先生在2015GPU技术大会的开幕主题演讲活动… 相较于当前的Maxwell处理器188bet金宝搏官网登录,NVID...
2025.12.16
人工智能一向不仅仅是数据、芯片和代码的集合,同样也是我们用来描述它的隐喻与叙事的产物。我们如何呈现这项技术,将决定公众想象中的AI模样,也影响人们如何设计、使用 AI,以及它对社会的实际影响。 CES作为全球规模最大、影响力最广的消费技术产业盛会之一,长期被视作全球科技领域的年度风向标,近年更成为...
2026.01.21
在当今数字化音乐创作的浪潮中,版权问题始终是音乐人心中的一块大石。每一次使用他人的音乐素材,都像在走钢丝金宝搏188BET下载,一不小心就可能陷入版权纠纷的漩涡。而随着AI技术在音乐领域的深度应用,一款名为《妙笔生歌》的AI智能创作音乐软件应运而生,它可以AI代唱demo,AI编曲作曲,AI给清唱哼唱作伴奏...
2026.01.21
本报告旨在为工业自动化领域的决策者,在2026年选择可编程逻辑控制器厂家时,提供一份客观、系统的决策参考。随着工业4.0与数字化转型的深入,PLC作为工业控制的核心,其选型不仅关乎设备稳定运行,更影响企业长期的智能化升级路径。面对市场上技术路线各异、品牌定位不同的众多厂家,决策者常面临如何在开放性、可靠性、...
2026.01.17
据法新社1月9日报道,8日,一名美国移民与海关执法局(ICE)执法人员在明尼阿波利斯开枪射杀一女子。数小时后,人工智能(AI)深度伪造的、关于受害者和开枪者的信息在网络上大量传播。这凸显出在重大新闻事件发生后金宝搏入口,专家们所说的“幻觉”内容越来越普遍。 法新社发现,社交平台上——主要是在X平台...
2026.01.11
在人工智能领域快速成长的深度学习技术是一项创新的计算引擎,可应用在从先进医药研究到全自动驾驶汽车的多元领域188bet金宝搏官网登录。NVIDIA联合创始人、总裁兼首席执行官黄仁勋先生在2015GPU技术大会的开幕主题演讲活动… 相较于当前的Maxwell处理器188bet金宝搏官网登录,NVID...
2025.12.16
人工智能一向不仅仅是数据、芯片和代码的集合,同样也是我们用来描述它的隐喻与叙事的产物。我们如何呈现这项技术,将决定公众想象中的AI模样,也影响人们如何设计、使用 AI,以及它对社会的实际影响。 CES作为全球规模最大、影响力最广的消费技术产业盛会之一,长期被视作全球科技领域的年度风向标,近年更成为...
2026.01.21
在当今数字化音乐创作的浪潮中,版权问题始终是音乐人心中的一块大石。每一次使用他人的音乐素材,都像在走钢丝金宝搏188BET下载,一不小心就可能陷入版权纠纷的漩涡。而随着AI技术在音乐领域的深度应用,一款名为《妙笔生歌》的AI智能创作音乐软件应运而生,它可以AI代唱demo,AI编曲作曲,AI给清唱哼唱作伴奏...
2026.01.21
本报告旨在为工业自动化领域的决策者,在2026年选择可编程逻辑控制器厂家时,提供一份客观、系统的决策参考。随着工业4.0与数字化转型的深入,PLC作为工业控制的核心,其选型不仅关乎设备稳定运行,更影响企业长期的智能化升级路径。面对市场上技术路线各异、品牌定位不同的众多厂家,决策者常面临如何在开放性、可靠性、...
2026.01.17
据法新社1月9日报道,8日,一名美国移民与海关执法局(ICE)执法人员在明尼阿波利斯开枪射杀一女子。数小时后,人工智能(AI)深度伪造的、关于受害者和开枪者的信息在网络上大量传播。这凸显出在重大新闻事件发生后金宝搏入口,专家们所说的“幻觉”内容越来越普遍。 法新社发现,社交平台上——主要是在X平台...
2026.01.11
在人工智能领域快速成长的深度学习技术是一项创新的计算引擎,可应用在从先进医药研究到全自动驾驶汽车的多元领域188bet金宝搏官网登录。NVIDIA联合创始人、总裁兼首席执行官黄仁勋先生在2015GPU技术大会的开幕主题演讲活动… 相较于当前的Maxwell处理器188bet金宝搏官网登录,NVID...
2025.12.16
人工智能一向不仅仅是数据、芯片和代码的集合,同样也是我们用来描述它的隐喻与叙事的产物。我们如何呈现这项技术,将决定公众想象中的AI模样,也影响人们如何设计、使用 AI,以及它对社会的实际影响。 CES作为全球规模最大、影响力最广的消费技术产业盛会之一,长期被视作全球科技领域的年度风向标,近年更成为...
2026.01.21
在当今数字化音乐创作的浪潮中,版权问题始终是音乐人心中的一块大石。每一次使用他人的音乐素材,都像在走钢丝金宝搏188BET下载,一不小心就可能陷入版权纠纷的漩涡。而随着AI技术在音乐领域的深度应用,一款名为《妙笔生歌》的AI智能创作音乐软件应运而生,它可以AI代唱demo,AI编曲作曲,AI给清唱哼唱作伴奏...
2026.01.21
本报告旨在为工业自动化领域的决策者,在2026年选择可编程逻辑控制器厂家时,提供一份客观、系统的决策参考。随着工业4.0与数字化转型的深入,PLC作为工业控制的核心,其选型不仅关乎设备稳定运行,更影响企业长期的智能化升级路径。面对市场上技术路线各异、品牌定位不同的众多厂家,决策者常面临如何在开放性、可靠性、...
2026.01.17
据法新社1月9日报道,8日,一名美国移民与海关执法局(ICE)执法人员在明尼阿波利斯开枪射杀一女子。数小时后,人工智能(AI)深度伪造的、关于受害者和开枪者的信息在网络上大量传播。这凸显出在重大新闻事件发生后金宝搏入口,专家们所说的“幻觉”内容越来越普遍。 法新社发现,社交平台上——主要是在X平台...
2026.01.11
在人工智能领域快速成长的深度学习技术是一项创新的计算引擎,可应用在从先进医药研究到全自动驾驶汽车的多元领域188bet金宝搏官网登录。NVIDIA联合创始人、总裁兼首席执行官黄仁勋先生在2015GPU技术大会的开幕主题演讲活动… 相较于当前的Maxwell处理器188bet金宝搏官网登录,NVID...
2025.12.16
人工智能一向不仅仅是数据、芯片和代码的集合,同样也是我们用来描述它的隐喻与叙事的产物。我们如何呈现这项技术,将决定公众想象中的AI模样,也影响人们如何设计、使用 AI,以及它对社会的实际影响。 CES作为全球规模最大、影响力最广的消费技术产业盛会之一,长期被视作全球科技领域的年度风向标,近年更成为...
2026.01.21
在当今数字化音乐创作的浪潮中,版权问题始终是音乐人心中的一块大石。每一次使用他人的音乐素材,都像在走钢丝金宝搏188BET下载,一不小心就可能陷入版权纠纷的漩涡。而随着AI技术在音乐领域的深度应用,一款名为《妙笔生歌》的AI智能创作音乐软件应运而生,它可以AI代唱demo,AI编曲作曲,AI给清唱哼唱作伴奏...
2026.01.21
本报告旨在为工业自动化领域的决策者,在2026年选择可编程逻辑控制器厂家时,提供一份客观、系统的决策参考。随着工业4.0与数字化转型的深入,PLC作为工业控制的核心,其选型不仅关乎设备稳定运行,更影响企业长期的智能化升级路径。面对市场上技术路线各异、品牌定位不同的众多厂家,决策者常面临如何在开放性、可靠性、...
2026.01.17
据法新社1月9日报道,8日,一名美国移民与海关执法局(ICE)执法人员在明尼阿波利斯开枪射杀一女子。数小时后,人工智能(AI)深度伪造的、关于受害者和开枪者的信息在网络上大量传播。这凸显出在重大新闻事件发生后金宝搏入口,专家们所说的“幻觉”内容越来越普遍。 法新社发现,社交平台上——主要是在X平台...
2026.01.11
在人工智能领域快速成长的深度学习技术是一项创新的计算引擎,可应用在从先进医药研究到全自动驾驶汽车的多元领域188bet金宝搏官网登录。NVIDIA联合创始人、总裁兼首席执行官黄仁勋先生在2015GPU技术大会的开幕主题演讲活动… 相较于当前的Maxwell处理器188bet金宝搏官网登录,NVID...
2025.12.16
人工智能一向不仅仅是数据、芯片和代码的集合,同样也是我们用来描述它的隐喻与叙事的产物。我们如何呈现这项技术,将决定公众想象中的AI模样,也影响人们如何设计、使用 AI,以及它对社会的实际影响。 CES作为全球规模最大、影响力最广的消费技术产业盛会之一,长期被视作全球科技领域的年度风向标,近年更成为...
2026.01.21
在当今数字化音乐创作的浪潮中,版权问题始终是音乐人心中的一块大石。每一次使用他人的音乐素材,都像在走钢丝金宝搏188BET下载,一不小心就可能陷入版权纠纷的漩涡。而随着AI技术在音乐领域的深度应用,一款名为《妙笔生歌》的AI智能创作音乐软件应运而生,它可以AI代唱demo,AI编曲作曲,AI给清唱哼唱作伴奏...
2026.01.21
本报告旨在为工业自动化领域的决策者,在2026年选择可编程逻辑控制器厂家时,提供一份客观、系统的决策参考。随着工业4.0与数字化转型的深入,PLC作为工业控制的核心,其选型不仅关乎设备稳定运行,更影响企业长期的智能化升级路径。面对市场上技术路线各异、品牌定位不同的众多厂家,决策者常面临如何在开放性、可靠性、...
2026.01.17
据法新社1月9日报道,8日,一名美国移民与海关执法局(ICE)执法人员在明尼阿波利斯开枪射杀一女子。数小时后,人工智能(AI)深度伪造的、关于受害者和开枪者的信息在网络上大量传播。这凸显出在重大新闻事件发生后金宝搏入口,专家们所说的“幻觉”内容越来越普遍。 法新社发现,社交平台上——主要是在X平台...
2026.01.11
在人工智能领域快速成长的深度学习技术是一项创新的计算引擎,可应用在从先进医药研究到全自动驾驶汽车的多元领域188bet金宝搏官网登录。NVIDIA联合创始人、总裁兼首席执行官黄仁勋先生在2015GPU技术大会的开幕主题演讲活动… 相较于当前的Maxwell处理器188bet金宝搏官网登录,NVID...
2025.12.16
人工智能一向不仅仅是数据、芯片和代码的集合,同样也是我们用来描述它的隐喻与叙事的产物。我们如何呈现这项技术,将决定公众想象中的AI模样,也影响人们如何设计、使用 AI,以及它对社会的实际影响。 CES作为全球规模最大、影响力最广的消费技术产业盛会之一,长期被视作全球科技领域的年度风向标,近年更成为...
2026.01.21
在当今数字化音乐创作的浪潮中,版权问题始终是音乐人心中的一块大石。每一次使用他人的音乐素材,都像在走钢丝金宝搏188BET下载,一不小心就可能陷入版权纠纷的漩涡。而随着AI技术在音乐领域的深度应用,一款名为《妙笔生歌》的AI智能创作音乐软件应运而生,它可以AI代唱demo,AI编曲作曲,AI给清唱哼唱作伴奏...
2026.01.21
本报告旨在为工业自动化领域的决策者,在2026年选择可编程逻辑控制器厂家时,提供一份客观、系统的决策参考。随着工业4.0与数字化转型的深入,PLC作为工业控制的核心,其选型不仅关乎设备稳定运行,更影响企业长期的智能化升级路径。面对市场上技术路线各异、品牌定位不同的众多厂家,决策者常面临如何在开放性、可靠性、...
2026.01.17
据法新社1月9日报道,8日,一名美国移民与海关执法局(ICE)执法人员在明尼阿波利斯开枪射杀一女子。数小时后,人工智能(AI)深度伪造的、关于受害者和开枪者的信息在网络上大量传播。这凸显出在重大新闻事件发生后金宝搏入口,专家们所说的“幻觉”内容越来越普遍。 法新社发现,社交平台上——主要是在X平台...
2026.01.11
在人工智能领域快速成长的深度学习技术是一项创新的计算引擎,可应用在从先进医药研究到全自动驾驶汽车的多元领域188bet金宝搏官网登录。NVIDIA联合创始人、总裁兼首席执行官黄仁勋先生在2015GPU技术大会的开幕主题演讲活动… 相较于当前的Maxwell处理器188bet金宝搏官网登录,NVID...
2025.12.16
人工智能一向不仅仅是数据、芯片和代码的集合,同样也是我们用来描述它的隐喻与叙事的产物。我们如何呈现这项技术,将决定公众想象中的AI模样,也影响人们如何设计、使用 AI,以及它对社会的实际影响。 CES作为全球规模最大、影响力最广的消费技术产业盛会之一,长期被视作全球科技领域的年度风向标,近年更成为...
2026.01.21
在当今数字化音乐创作的浪潮中,版权问题始终是音乐人心中的一块大石。每一次使用他人的音乐素材,都像在走钢丝金宝搏188BET下载,一不小心就可能陷入版权纠纷的漩涡。而随着AI技术在音乐领域的深度应用,一款名为《妙笔生歌》的AI智能创作音乐软件应运而生,它可以AI代唱demo,AI编曲作曲,AI给清唱哼唱作伴奏...
2026.01.21
本报告旨在为工业自动化领域的决策者,在2026年选择可编程逻辑控制器厂家时,提供一份客观、系统的决策参考。随着工业4.0与数字化转型的深入,PLC作为工业控制的核心,其选型不仅关乎设备稳定运行,更影响企业长期的智能化升级路径。面对市场上技术路线各异、品牌定位不同的众多厂家,决策者常面临如何在开放性、可靠性、...
2026.01.17
据法新社1月9日报道,8日,一名美国移民与海关执法局(ICE)执法人员在明尼阿波利斯开枪射杀一女子。数小时后,人工智能(AI)深度伪造的、关于受害者和开枪者的信息在网络上大量传播。这凸显出在重大新闻事件发生后金宝搏入口,专家们所说的“幻觉”内容越来越普遍。 法新社发现,社交平台上——主要是在X平台...
2026.01.11
在人工智能领域快速成长的深度学习技术是一项创新的计算引擎,可应用在从先进医药研究到全自动驾驶汽车的多元领域188bet金宝搏官网登录。NVIDIA联合创始人、总裁兼首席执行官黄仁勋先生在2015GPU技术大会的开幕主题演讲活动… 相较于当前的Maxwell处理器188bet金宝搏官网登录,NVID...
2025.12.16
人工智能一向不仅仅是数据、芯片和代码的集合,同样也是我们用来描述它的隐喻与叙事的产物。我们如何呈现这项技术,将决定公众想象中的AI模样,也影响人们如何设计、使用 AI,以及它对社会的实际影响。 CES作为全球规模最大、影响力最广的消费技术产业盛会之一,长期被视作全球科技领域的年度风向标,近年更成为...
2026.01.21
在当今数字化音乐创作的浪潮中,版权问题始终是音乐人心中的一块大石。每一次使用他人的音乐素材,都像在走钢丝金宝搏188BET下载,一不小心就可能陷入版权纠纷的漩涡。而随着AI技术在音乐领域的深度应用,一款名为《妙笔生歌》的AI智能创作音乐软件应运而生,它可以AI代唱demo,AI编曲作曲,AI给清唱哼唱作伴奏...
2026.01.21
本报告旨在为工业自动化领域的决策者,在2026年选择可编程逻辑控制器厂家时,提供一份客观、系统的决策参考。随着工业4.0与数字化转型的深入,PLC作为工业控制的核心,其选型不仅关乎设备稳定运行,更影响企业长期的智能化升级路径。面对市场上技术路线各异、品牌定位不同的众多厂家,决策者常面临如何在开放性、可靠性、...
2026.01.17
据法新社1月9日报道,8日,一名美国移民与海关执法局(ICE)执法人员在明尼阿波利斯开枪射杀一女子。数小时后,人工智能(AI)深度伪造的、关于受害者和开枪者的信息在网络上大量传播。这凸显出在重大新闻事件发生后金宝搏入口,专家们所说的“幻觉”内容越来越普遍。 法新社发现,社交平台上——主要是在X平台...
2026.01.11
在人工智能领域快速成长的深度学习技术是一项创新的计算引擎,可应用在从先进医药研究到全自动驾驶汽车的多元领域188bet金宝搏官网登录。NVIDIA联合创始人、总裁兼首席执行官黄仁勋先生在2015GPU技术大会的开幕主题演讲活动… 相较于当前的Maxwell处理器188bet金宝搏官网登录,NVID...
2025.12.16
人工智能一向不仅仅是数据、芯片和代码的集合,同样也是我们用来描述它的隐喻与叙事的产物。我们如何呈现这项技术,将决定公众想象中的AI模样,也影响人们如何设计、使用 AI,以及它对社会的实际影响。 CES作为全球规模最大、影响力最广的消费技术产业盛会之一,长期被视作全球科技领域的年度风向标,近年更成为...
2026.01.21
在当今数字化音乐创作的浪潮中,版权问题始终是音乐人心中的一块大石。每一次使用他人的音乐素材,都像在走钢丝金宝搏188BET下载,一不小心就可能陷入版权纠纷的漩涡。而随着AI技术在音乐领域的深度应用,一款名为《妙笔生歌》的AI智能创作音乐软件应运而生,它可以AI代唱demo,AI编曲作曲,AI给清唱哼唱作伴奏...
2026.01.21
本报告旨在为工业自动化领域的决策者,在2026年选择可编程逻辑控制器厂家时,提供一份客观、系统的决策参考。随着工业4.0与数字化转型的深入,PLC作为工业控制的核心,其选型不仅关乎设备稳定运行,更影响企业长期的智能化升级路径。面对市场上技术路线各异、品牌定位不同的众多厂家,决策者常面临如何在开放性、可靠性、...
2026.01.17
据法新社1月9日报道,8日,一名美国移民与海关执法局(ICE)执法人员在明尼阿波利斯开枪射杀一女子。数小时后,人工智能(AI)深度伪造的、关于受害者和开枪者的信息在网络上大量传播。这凸显出在重大新闻事件发生后金宝搏入口,专家们所说的“幻觉”内容越来越普遍。 法新社发现,社交平台上——主要是在X平台...
2026.01.11
在人工智能领域快速成长的深度学习技术是一项创新的计算引擎,可应用在从先进医药研究到全自动驾驶汽车的多元领域188bet金宝搏官网登录。NVIDIA联合创始人、总裁兼首席执行官黄仁勋先生在2015GPU技术大会的开幕主题演讲活动… 相较于当前的Maxwell处理器188bet金宝搏官网登录,NVID...
2025.12.16
人工智能一向不仅仅是数据、芯片和代码的集合,同样也是我们用来描述它的隐喻与叙事的产物。我们如何呈现这项技术,将决定公众想象中的AI模样,也影响人们如何设计、使用 AI,以及它对社会的实际影响。 CES作为全球规模最大、影响力最广的消费技术产业盛会之一,长期被视作全球科技领域的年度风向标,近年更成为...
2026.01.21
在当今数字化音乐创作的浪潮中,版权问题始终是音乐人心中的一块大石。每一次使用他人的音乐素材,都像在走钢丝金宝搏188BET下载,一不小心就可能陷入版权纠纷的漩涡。而随着AI技术在音乐领域的深度应用,一款名为《妙笔生歌》的AI智能创作音乐软件应运而生,它可以AI代唱demo,AI编曲作曲,AI给清唱哼唱作伴奏...
2026.01.21
本报告旨在为工业自动化领域的决策者,在2026年选择可编程逻辑控制器厂家时,提供一份客观、系统的决策参考。随着工业4.0与数字化转型的深入,PLC作为工业控制的核心,其选型不仅关乎设备稳定运行,更影响企业长期的智能化升级路径。面对市场上技术路线各异、品牌定位不同的众多厂家,决策者常面临如何在开放性、可靠性、...
2026.01.17
据法新社1月9日报道,8日,一名美国移民与海关执法局(ICE)执法人员在明尼阿波利斯开枪射杀一女子。数小时后,人工智能(AI)深度伪造的、关于受害者和开枪者的信息在网络上大量传播。这凸显出在重大新闻事件发生后金宝搏入口,专家们所说的“幻觉”内容越来越普遍。 法新社发现,社交平台上——主要是在X平台...
2026.01.11
在人工智能领域快速成长的深度学习技术是一项创新的计算引擎,可应用在从先进医药研究到全自动驾驶汽车的多元领域188bet金宝搏官网登录。NVIDIA联合创始人、总裁兼首席执行官黄仁勋先生在2015GPU技术大会的开幕主题演讲活动… 相较于当前的Maxwell处理器188bet金宝搏官网登录,NVID...
2025.12.16
人工智能一向不仅仅是数据、芯片和代码的集合,同样也是我们用来描述它的隐喻与叙事的产物。我们如何呈现这项技术,将决定公众想象中的AI模样,也影响人们如何设计、使用 AI,以及它对社会的实际影响。 CES作为全球规模最大、影响力最广的消费技术产业盛会之一,长期被视作全球科技领域的年度风向标,近年更成为...
2026.01.21
在当今数字化音乐创作的浪潮中,版权问题始终是音乐人心中的一块大石。每一次使用他人的音乐素材,都像在走钢丝金宝搏188BET下载,一不小心就可能陷入版权纠纷的漩涡。而随着AI技术在音乐领域的深度应用,一款名为《妙笔生歌》的AI智能创作音乐软件应运而生,它可以AI代唱demo,AI编曲作曲,AI给清唱哼唱作伴奏...
2026.01.21
本报告旨在为工业自动化领域的决策者,在2026年选择可编程逻辑控制器厂家时,提供一份客观、系统的决策参考。随着工业4.0与数字化转型的深入,PLC作为工业控制的核心,其选型不仅关乎设备稳定运行,更影响企业长期的智能化升级路径。面对市场上技术路线各异、品牌定位不同的众多厂家,决策者常面临如何在开放性、可靠性、...
2026.01.17






